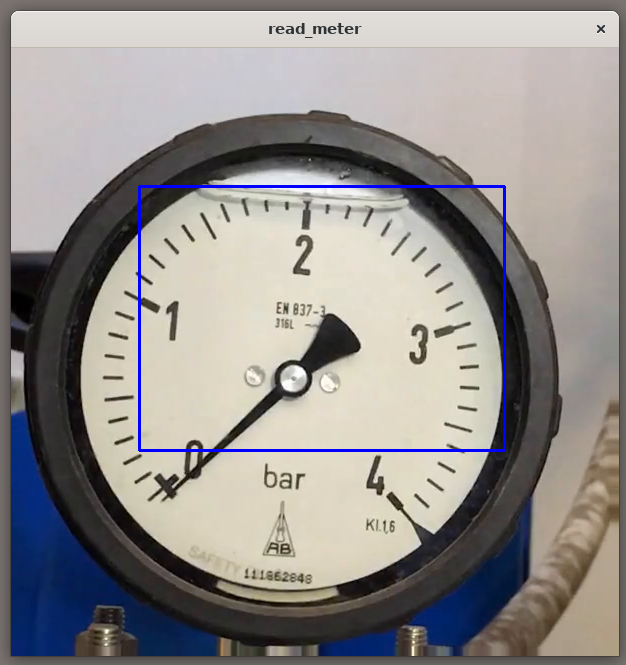
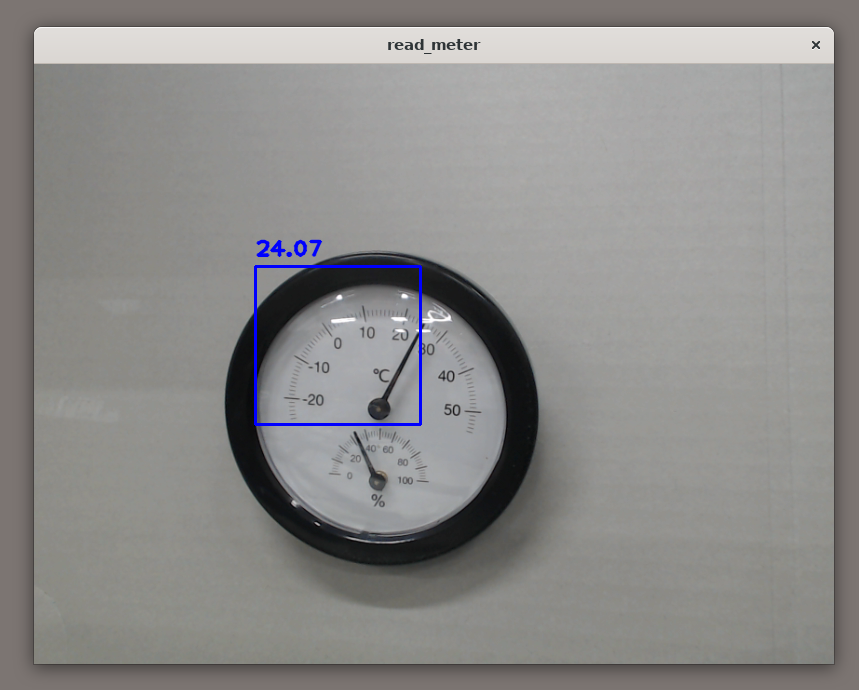
今回行う物体検出における転移学習では、既存の物体検出用の推論モデルであるMobileNet SSD v2をベースに、新たに検出させたい物が写った画像を含む教師データを用意して学習させることで、対象物を検出するモデルを効率よく作成します。
まずは教師データの元となる画像を収集します。
一から推論モデルを学習するのであれば数千枚ほどのデータがほしいところですが、今回は転移学習を用いるため、最低100枚程度からある程度の精度を出せます。
表6.1「画像収集に使用できるツール」に示すように、様々な機械学習向けに画像を収集できるツールが公開されているので、そちらを利用することで効率よく画像を集めることができます。
上記の他にも、機械学習などで使用できる画像を収集できるツールやWebサイトなどが存在しているので、興味のある方は調べてみてください。
![[警告]](images/warning.png) | |
|---|
第三者がアップロードした画像を学習に使用する際には、著作権などの法律を十分に確認した上で、ご自身の責任において画像の収集・利用をして頂くようお願いします。 |
今回はGoogle Images Downloadを使用して、画像データを収集していきます。
まずインストールについてですが、Google Images Downloadはpipでインストールできます。
しかし執筆時点では最新のGoogle画像検索APIに対応できていませんので、有志がパッチを適用したものをインストールします。
Google Images Downloadのインストール時に必要なパッケージも合わせてインストールします。
Google Images Downloadを使用して、gauge(アナログメーター)の画像を収集します。
Google Images Downloadは、ダウンロードする画像の拡張子と縦横のサイズ、ダウンロードする数を指定することができます。
ここでは、Googleで"gauge"と画像検索した際に得られる画像をjpg形式で100枚ダウンロードします。
|
作業ディレクトリを作成し、移動します。
|
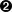
|
Google Images Downloadを実行します。
|

|
ファイルによってはエラーとなるものがあり、必ずしも指定した枚数の画像を収集できるとは限りません。
|
Google Images Downloadを用いて100枚より多くの画像を収集する際には、別途Google Chromeとchromedriverをインストールする必要があります。
詳しくは 公式ドキュメントを参照してください。
図6.8「Google Images Downloadの実行」の実行例ならば98枚のgaugeで画像を検索した際の結果が得られました。
また、場合によっては壊れたファイルをダウンロードしてくる場合がありますので、その場合は適宜手動で削除してください。
その後、図6.10「画像ファイルを連番でリネーム」を実行して、ファイル名をリネームしておきます。
画像が用意できたら、次はその画像内のどこに何が写っているかを示すラベル付け(アノテーション)を行っていきます。
画像データの数によりますが、推論モデル学習の一連の流れの中で一番工数がかかる手順がこのアノテーション作業です。
表6.2「物体検出アノテーションに使用できるツール」にアノテーションする際によく使われるツールをまとめました。どれもWindows/Linux共に使用可能ですので、お好きなものをご使用ください。
表6.2 物体検出アノテーションに使用できるツール
| ツール名 | 概要 |
|---|
labelImg | Python+Qtで記述されたオープンソースアノテーションソフトウェア |
VoTT | Microsoft社が提供しているオープンソースアノテーションソフトウェア |
Labelbox | リッチなGUIで多機能なLabelbox社製ツール。基本無料で利用量が一定を超えると課金される点に注意 |
本ドキュメントでは、labelImgを使用してアノテーションを行っていきます。
labelImgは図6.11「labelImgをインストールする」に示すコマンドを実行することでインストールできます。
labelImgを起動するには、図6.12「Linux環境におけるlabelImg実行例」に示すコマンドを実行します。
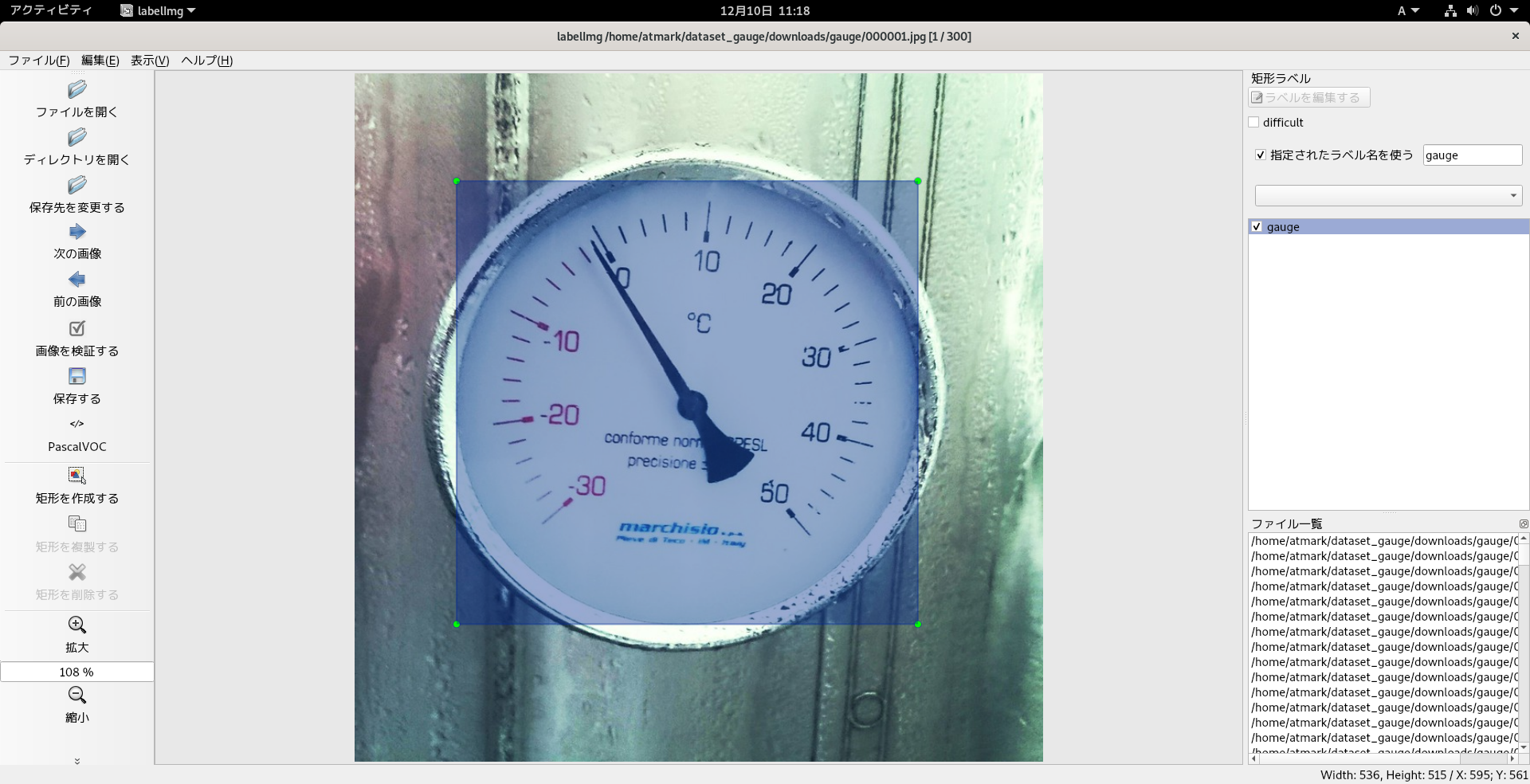
実行すると、図6.13「labelImgの起動」のようなlabelImgのアプリケーションウィンドウが立ち上がります。
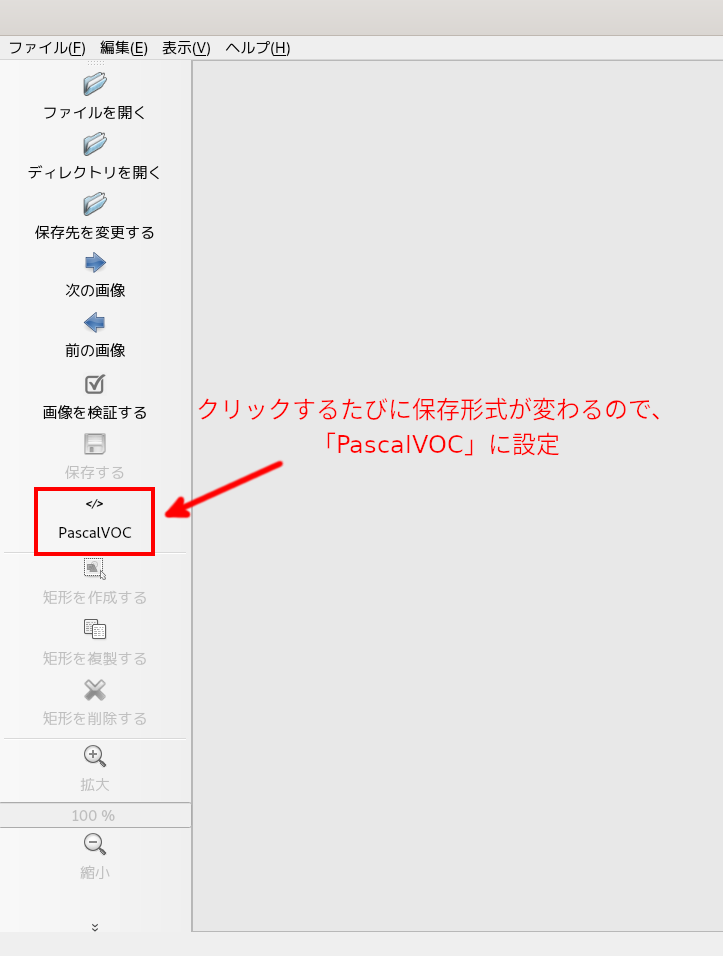
まず、アノテーション情報の保存形式を指定します。
今回はPascalVOC形式で保存します。
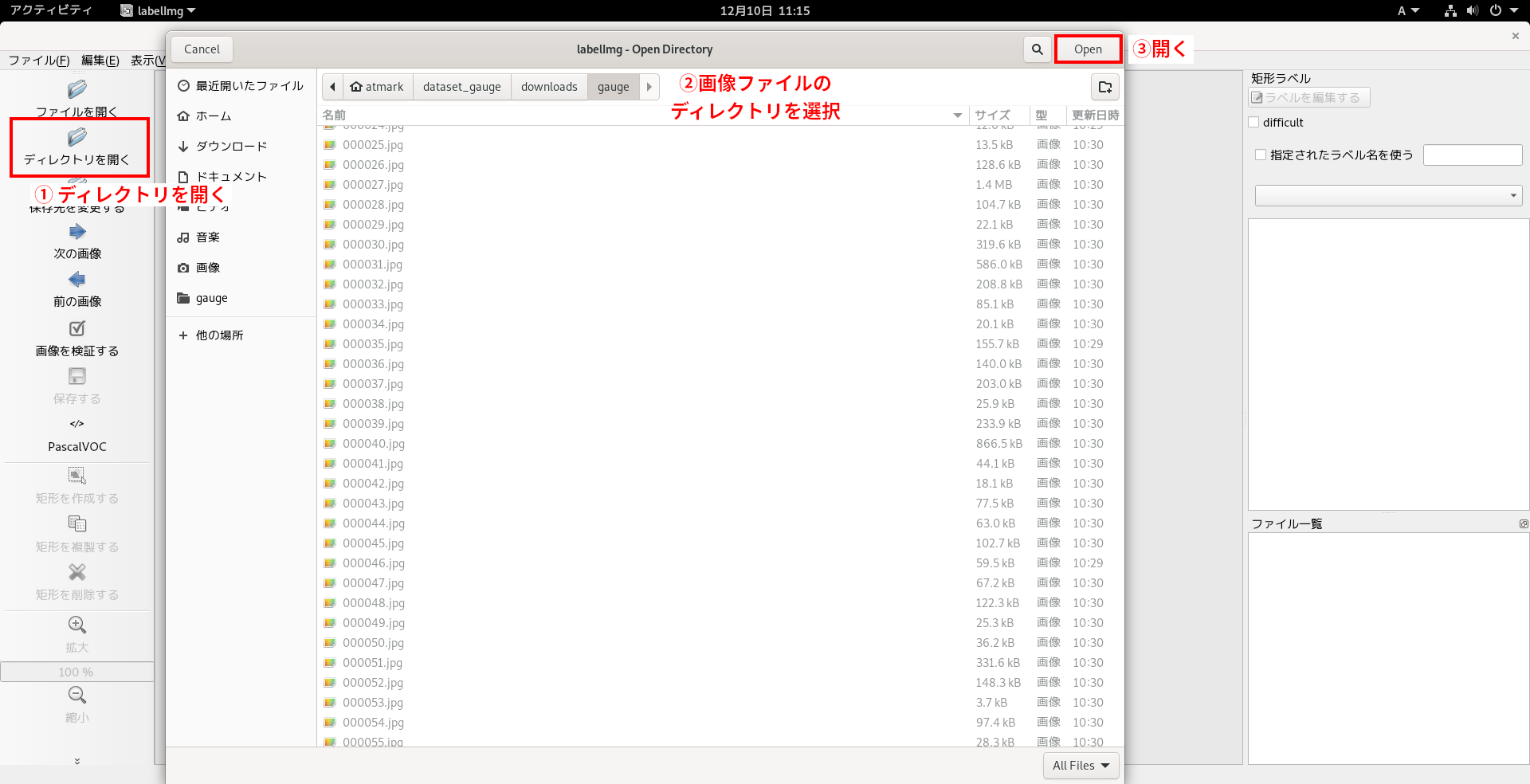
アノテーションを開始するために、画面左の「ディレクトリを開く」をクリックして、アノテーションしたい画像が入ったディレクトリ(今回は~/dataset_gauge/downloads/gauge/)を指定します。
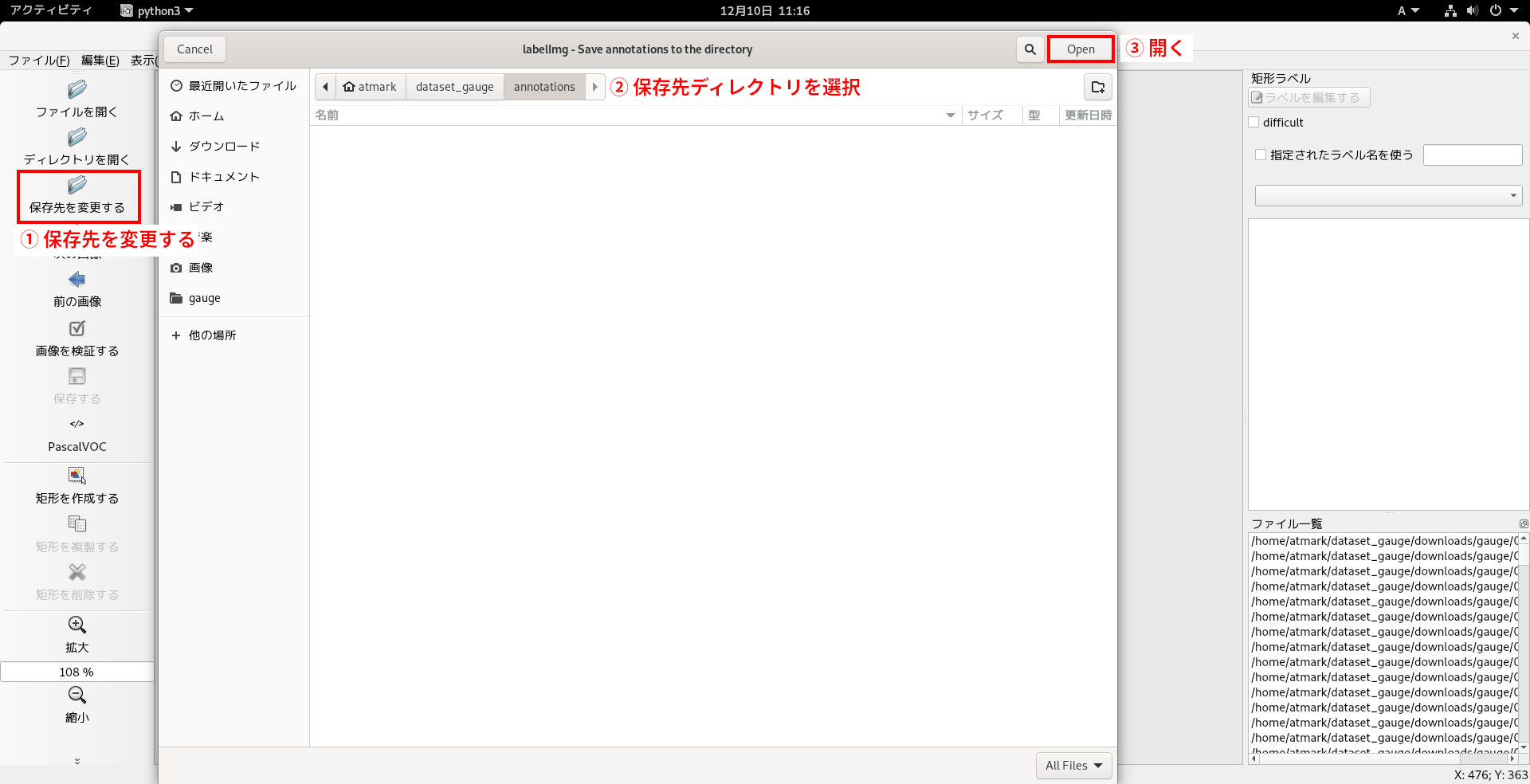
さらに、アノテーション情報をどこに保存するかを設定します。
画面左の「保存先を変更する」をクリックして、アノテーション情報を保存したいディレクトリ(今回は~/dataset_gauge/annotations/)を指定します。
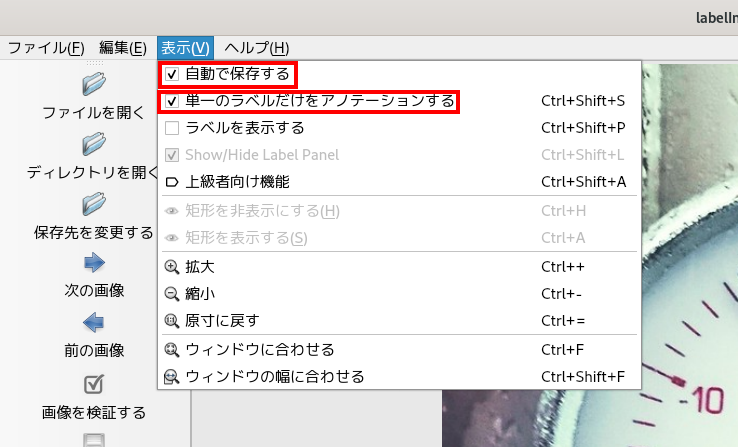
その後作業効率化のために、画面上部のツールバーの[表示]から、以下を有効化をしておくことをお勧めします。
-
自動で保存する
-
単一のラベルだけをアノテーションする
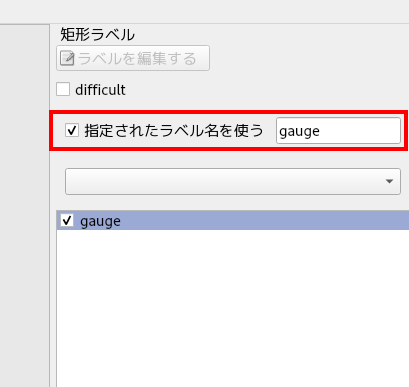
さらに、画面右側にて、「指定されたラベル名を使う」にチェックを入れ、ラベル名を「gauge」とします。
表6.3「labelImgでよく使用するショートカットキー一覧」に、labelImgを使用したアノテーション作業中によく用いるショートカットキーを示します。
作業効率化のために使用することをお勧めします。
詳しくは、labelImgの画面上部のツールバーの[ヘルプ]→[ショートカット一覧を見る(英語)]から確認できます。
表6.3 labelImgでよく使用するショートカットキー一覧
| ショートカットキー | 役割 |
|---|
W | 矩形選択モードに切り替え |
D | 次の画像へ |
A | 前の画像へ |
上記設定後、Wキーを押下して矩形選択モードに切り替え、マウス左ドラッグで画像内の対象物を選択します。
選択すると自動的に選択範囲がgaugeでラベル付けされます。
Dキー押下で次の画像へ切り替えられます。
以上の手順を用意した全ての画像に対して行っていきます。
アノテーションする際の注意事項としまして以下が挙げられます。
アノテーションが完了したら、保存先のディレクトリにアノテーション情報(.xmlファイル)が保存されていることを確認してください。
次に、label_map.pbtxtというファイルを~/dataset_gauge/xmls/内に作成します。
物体検出は、画像を推論モデルに入力し、結果として「どこに」、「何が」あるかが返ってくるのですが、「何が」の部分は1から始まるIDで返ってきます。
label_map.pbtxtは、そのIDとラベル名を紐付けるファイルです。
本サンプルアプリケーションでは"gauge"のみを認識し、画面上にはメーターが指し示す値を表示させる仕様なので、アプリケーション本体ではこのラベルファイルは使用しません。
しかし、この後の推論モデルの学習時に使用するので、ここで作成しておきます。
今回作成するlabel_map.pbtxtの内容を図6.21「label_map.pbtxt作成例」に示します。
以上でアノテーション作業は完了です。







 |-- parameter_sample.json
|-- parameter_sample.json  `-- read_meter
`-- read_meter