この章では、C言語を使用した実践的なプログラミングを取り上げます。 一口にプログラミングといっても、ちょっとしたファイルの読み書きやデバイス操作を実現するだけの簡単なものから、複雑な演算を行ったりネットワークを介してサービスを提供し続けるような高度なものまで、多岐に渡ります。ここではその中から、誰もが様々な場面で使うであろう基本的技術と、Armadilloが持つインターフェースを通じて行う操作の代表的なものを中心に、分野ごとに分けて紹介していきます。 Linuxや開発環境に依存した独特な部分に留意しつつ、組み込みならではの使用方法を想定した応用例やノウハウについても多く記載したつもりです。プログラミング経験豊富な方であってもおさらいのつもりで読んでみて、一般的なプログラミング本では解説されていない情報を見つけていただければ幸いです。 C言語で書かれたプログラムは、実行できる状態にするためにコンパイルが必要です。このためのツールがCコンパイラでありツールチェーンですが、この他にも一連のビルド作業を手助けしてくれる色々なツールが存在します。C言語プログラミングのための基礎知識として、これらビルド用ツールの機能や使い方について説明します。 第1部「開発の基本的な流れ」の「アプリケーションプログラムの作成」で説明したように、C言語で記述したソースコードのコンパイルにはgcc(GNU C Compiler[])を使用します。 gccはいくつかの動作形態を持っており、また多くの機能を備えています。これらはgccに与えるコマンドラインオプションにより制御されますが、このオプションはかなりの多種に及びます。ここでは、gccを使いこなすために必須といえるオプションをピックアップして紹介します。 gccにソースファイル名のみを与えると、コンパイル、アセンブル、リンクの一連の処理を自動で行って、実行ファイルを出力します。これが基本動作です。 -o 出力ファイル名オプションを付けることで、出力ファイルの名前を指定することができます。このオプションを付けなかった場合、実行ファイルはa.outという名前になります。
-cオプションを付けると、コンパイルからアセンブルまでを行い、リンク処理を行いません。出力ファイルは、アセンブラが出力したオブジェクトファイルになります。
-Wで始まるものは、警告オプションです。コンパイル時の警告表示を制御することができます。
本書のサンプルプログラムでは、バグを生みやすいコードの書き方をしていれば警告表示が出るように、コンパイル時のオプションとして-Wallと-Wextraを必ず指定するようにしています。これらのオプションを付けても警告が出ないような書き方を目指すことで、C言語の構文が原因であるバグの大半を防ぐことができます。 -Oで始まるものは、最適化オプションです。コンパイラの最適化レベルを制御することができます。
-O0は、最適化を行いません。最適化オプション未指定のときも同じ動作です。
-O1では、コードサイズと実行時間を小さくするいくつかの最適化を行います。-Oのように数字をつけなかったときも、この動作になります。
-O2では、サポートするほとんどの種類の最適化を行います。ただし、コードサイズと実行速度のどちらかを大きく犠牲にするようなもの(例えば関数の自動インライン化)は、このレベルには含まれません。
-O3では、さらに高速にするための最適化を行います。コードサイズは大きくなるが実行速度を稼ぐことのできる関数の自動インライン化は、このレベルで有効になります。
-Osでは、コードサイズが小さくなるように最適化を行います。-O2で有効になる最適化のうちコードサイズが大きくならないものすべてに加え、さらにコードサイズが小さくなるように設計された特別な最適化も行います。
6.1.1.4. 処理対象となるディレクトリやファイルを追加するオプション-Iディレクトリ名オプションを付けると、ヘッダファイルの検索対象に指定ディレクトリが追加されます。ここで指定したディレクトリは、標準のシステムインクルードディレクトリよりも先に検索されます。
-iquoteディレクトリ名
オプションを付けると、ローカルヘッダファイル(#include "ヘッダファイル名"という形で、ダブルクォート囲みでヘッダ指定したもの)の検索対象に指定ディレクトリが追加されます。システムヘッダファイル(#include <ヘッダファイ
ル名>と指定したもの)については、この指定ディレクトリからは検索されません。
-Lや-lは、リンク時のリンカ動作に影響を与えるオプションです。
-Lディレクトリ名オプションを付けると、ライブラリファイルの検索対象に指定ディレクトリが追加されます。
-lライブラリ名オプションを付けると、libライブラリ名
.soまたはlibライ
ブラリ名.aという名前のライブラリファイルを検索し、リンクします。
PCには一般的にx86と呼ばれる種類のプロセッサが搭載されていますが、Armadilloに搭載されているプロセッサはARMコアを採用したものです。各々のプロセッサ固有の機能を制御するときは、-mで始まるオプションを使用します。 ARMプロセッサ固有のオプションには、アーキテクチャや浮動小数点演算ユニット、ABIの種類などを指定するものがあります。 -march=アーキテクチャ名
を付けると、指定アーキテクチャ向けのインストラクションセットを用いたコンパイルが行われます。
![[注記]](images/note.png) | ARMインストラクションセットの互換性 |
|---|
ARMのインストラクションセットは、後方互換性が維持されています[]。このため異なるプロセッサを搭載したマシン間であっても、より古い方のアーキテクチャを指定してコンパイルすることで、バイナリレベルでの互換性を保つことができます。しかしながら、新しいアークテクチャ上で古いアーキテクチャ向けのインストラクションセットを使用することは、使用可能な新しいインストラクション(例えば、ARMv3まではハーフワード単位の入出力インストラクションが使えません)を使用しないことになりますから、実行効率面から見ればもったいない状態になります。 この辺りのバランスを考えて、Debian GNU/LinuxのARMバイナリはARMv4(-march=armv4)向けとしてコンパイルされたものになっており、ARMv5TEJ(-march=armv5te)コアを持つArmadillo-400シリーズ上でそのまま動作します。一方、UbuntuのARMバイナリは、より実行効率を優先したものになっているようです。Ubuntu 10.04ではARMv7(-march=armv7-a)向けとされており、Armadillo-400シリーズ上では動作しないバイナリになっています。 |
ツールチェーンには、Cコンパイラ(gcc)を始めとして、Cプリプロセッサ(cpp)、アセンブラ(as)、リンカ(ld)、アーカイバ(ar)、デバッガ(gdb) などが含まれます。ARM向けにクロス開発する際は、クロスツールチェーンを使用します。 第1部「開発基本的な流れ」の「アプリケーションプログラムの作成」で説明したように、作業用PC上でARM向けにクロスコンパイルする際にはarm-linux-gnueabi-gccを使用します。このコマンド名の前に付いているarm-linux-gnueabi-の部分を、プレフィックス(前頭詞)といいます。 クロスツールチェーンは、すべてこのプレフィックスが付いたコマンド名になっています。例えばARMクロスアセンブラであればarm-linux-gnueabi-as、ARMクロスリンカであればarm-linux-gnueabi-ldになります。 第1部「開発の基本的な流れ」の「make」で紹介したように、C言語で開発する際にはコンパイル、アセンブル、リンクといった一連のビルド作業を自動化するために、makefileを記述してmakeを使用することが一般的です。 ここではmakeの使い方と、makefileの書き方について紹介します。 makeは、プログラムのビルドを簡単にするツールです。makefileにプログラムのビルド手順ルールを記述しておくと、makeはそのルールに従って次に行うべき手順を自動的に見つけ出し、必要なコマンドだけを実行してくれます。 何のオプションも付けずにmakeを実行すると、カレントディレクトリにあるGNUmakefile、makefile、Makefileといった順にファイルを検索し、最初に見つかったものをルールとして使用します[]。 -C ディレクトリ名オプションを使用して指定したディレクトリに移動した状態で実行したり、-f ファイル名オプションを使用して指定したファイル名をmakefileとして読み込むことなども可能です。
![[ティップ]](images/tip.png) | makeの詳細情報 |
|---|
gccと同様に、makeのオプションやmakefileの書き方などの詳細情報については、infoページが充実しています。 makeのinfoページはmake-docパッケージに含まれており、ATDEなどのDebian環境ではaptitudeやapt-getコマンドでインストールすることができます。 |
6.1.3.2. makefileへのルールの記述makeは、makefileに記載されたルールに従ってビルドを行います。このルールの書き方について説明します。 makefileには、複数のルールを記述することができます。1つのルールは必ず1つのターゲットを持ち、このターゲットがそのルールで生成されるファイルとなります。ターゲットと組み合わせて、そのターゲットを生成するための依存ファイル(事前に必要なファイル)の名称と、実行するコマンドラインを記述します。 依存ファイルは、ターゲット名:の後にスペース区切りで複数記述することができます。コマンドラインは、次の行の先頭からタブ(スペースではありません)を入力した後に記述します。コマンドラインを複数行書くことも可能です。 複数のルールが記述されたmakefileに対しmakeを実行すると、一番上に記述されているターゲットに対するルールのみが適用されます。このターゲット(図6.1「ルールの記述方法」でいえばターゲット1)を、デフォルトゴールと呼びます。 デフォルトゴール以外のターゲットを指定してmakeしたい場合、makeにターゲット名を与えて実行します。図6.1「ルールの記述方法」でターゲット2をmakeする場合は、make ターゲット2になります。 図6.2「ルールの記述方法2」のように、別のルールのターゲットを依存ファイルとして指定することが可能です。この場合、ターゲット1を生成するためにターゲット2が必要となるため、先にコマンドライン2が実行されます。 あるルールを適用する際に、必ずコマンドラインが実行されるわけではありません。makeはルールを評価する際、必ずターゲットの存在と更新日時を確認します。ターゲットが存在しない場合、またはターゲットの更新日時より依存ファイルのいずれかの更新日時が新しくなっていた場合のみ、コマンドラインを実行します。 つまり、2回目以降にmakeした際は、依存ファイルが更新されたルールのコマンドラインのみが実行されるわけです。このように、makeはビルド時間を短縮してくれます。 より実際に近い、makefileの例を見てみます。 図6.3「makefileの実例」では、デフォルトゴールはtarget1です。target1はtarget2に依存するので、target2がない場合は先にtarget2を作成しにいきます。 target2は、depend1とdepend2に依存します。target2という名前のファイルがないか、target2が作られた後にdepend1やdepend2が変更されていた場合、下のコマンドライン2行が実行されます。 target2が存在してtarget1という名前のファイルがない場合、またはtarget1作成後にtarget2が再作成されていた場合、cat target2が実行されます。この例ではtarget1が作成されることはありませんので、makeをするたびに毎回cat target2が実行されることになります。 図6.3「makefileの実例」をMakefileという名前でファイル保存し、適当な内容のファイルdepend1とdepend2を作成してからmakeすると、以下のように動作します。 
| Makefileと依存ファイルを用意します。 | 
| depend1はhello、depend2はworldと書かれたテキストファイルです。 | 
| makeすると、target1に対するルールが適用されます。 | 
| target1はtarget2に依存するので、target2に対するルールが適用されコマンドラインが実行されます。 | 
| target2が作成されると、target1のためのコマンドラインが実行されます。 | 
| target2が作成されています。 | 
| target2をmakeしますが、既に存在するtarget2が依存ファイルより新しいので、何も実行されません。 | 
| target2の依存ファイルを変更してみます。 | 
| target2をmakeすると、今度は依存ファイルが更新されているので、コマンドラインが実行されます。 | 
| target1が作成されることはないので、target1に対するコマンドラインは毎回実行されます。 |
makefile内では、変数[]を使うことができます。 変数名には、前後がスペースでなく、「:」(コロン)、「#」(ナンバー記号[])、「=」(イコール)を含まない文字列を使用できますが、通常は英数字と「_」(アンダースコア)のみで構成するのが無難です。なお、大文字と小文字は区別されます。 変数の定義は、変数名 = 値という形式で初期値を代入することによって成されます。シェルスクリプトの場合とは異なり、=の前後にはスペースを入れることができます。変数の値は文字列、または文字列のリストです。リストの場合は、変数名 = 値1 値2 ...と、スペースで値を区切って指定します。 変数を参照するには、$(変数名)または${変数名}とします。変数を参照すると展開され、展開された文字列と置き換えられます。 変数名 = 値という形式で定義された変数は、正確には再帰展開変数(recursivery expanded variable)といいます。再帰展開変数は記述されたままの形で値を保持し、参照するまで展開されません。そのため、 FOO = foo $(BAR)
BAR = bar baz と定義することができます。このとき、$(FOO)を展開すると「foo bar baz」となります。ただし、 FOO = foo
FOO = $(FOO) bar baz とすると無限ループになるため、定義することはできません。 変数は、変数名 := 値という形式でも定義することができます。この形式で定義された変数を、単純展開変数(simply expanded variable)といいます。単純展開変数は、定義された時点で値を展開して保持します。そのため以下のように記述することで、変数に値を追加することができます。 FOO := foo
FOO := $(FOO) bar baz また、変数名 += 値とすることでも変数に文字列を追加できます。 FOO = foo bar
FOO += baz とした場合、$(FOO)を展開すると「foo bar baz」となります。+=で文字列を追加した場合、追加する文字列の前に半角スペースが一つ追加されます。展開がいつ行われるかは、文字列を追加する変数がどのように定義されたかに準じます。再帰展開変数に+=で文字列を追加した場合、参照の際に展開されます。また、単純展開変数に文字列を追加した場合は、代入の際に展開されます。 変数定義は、以下のように書くこともできます。 FOO ?= bar こうすると変数FOOが定義されていない場合だけ、変数FOOに「bar」を代入します。 6.1.3.4. makefileで使用される暗黙のルールと定義済み変数makefileでは、よく使われるルールは明示的に記述しなくても暗黙のルールとして適用されます。 C/C++言語のソースファイルをビルドする際に適用される暗黙のルールには、以下のものがあります。 Cプログラムのコンパイル オブジェクトファイル(.o)が、Cソースファイル(.c)から$(CC) -c $(CPPFLAGS) $(CFLAGS) Cソースファイル名
というコマンドラインで生成されます。 C++プログラムのコンパイル オブジェクトファイル(.o)が、C++ソースファイル(.cc/.cpp/.Cのいずれか)から$(CXX) -c $(CPPFLAGS) $(CXXFLAGS)
C++ソースファイル名というコマンドラインで生成されます。 アセンブラソースのプリプロセス プリプロセス済みアセンブラソースファイル(.s)が、アセンブラソース(.S)から$(CPP) $(CPPCFLAGS) アセンブラソース名
というコマンドラインで生成されます。 プリプロセス済みアセンブラソースのアセンブル オブジェクトファイル(.o)が、プリプロセス済みアセンブラソースファイル(.s)から$(AS) $(ASFLAGS) プリプロセス済みアセ
ンブラソースファイル名というコマンドラインで生成されます。 リンク 実行ファイル(拡張子なし)が、オブジェクトファイル(.o)から$(CC) $(LDFLAGS) オブジェクトファイル名
$(LOADLIBES) -o 実行ファイル名
というコマンドラインで生成されます。 このルールは、複数のオブジェクトファイルに対して適用することもできます。ルールに、実行ファイル名:オブジェクト1ファイル名 オブジェクト2ファイル名とだけ記述しておくと、オブジェクト1ファイルとオブジェクト2ファイルをルールに従って生成した後、2つのオブジェクトファイルから実行ファイルを生成します。
ここに登場したCCやCFLAGSといった変数は、暗黙のうちに定義されている変数です。主なものを挙げます。 表6.1 暗黙のルールで使用される変数 | 変数名 | デフォルト値 | 説明
|
|---|
AR | ar | アーカイバ | AS | as | アセンブラ | CC | cc | Cコンパイラ。Linuxシステムでは、ccはgccコマンドへのリンクになっています。 | CXX | g++ | C++コンパイラ | CPP | $(CC) -E | Cプリプロセッサ | RM | rm -f | ファイル削除コマンド | ARFLAGS | rv | アーカイバに渡されるフラグ | ASFLAGS | | アセンブラに渡される拡張フラグ | CFLAGS | | Cコンパイラに渡される拡張フラグ | CXXFLAGS | | C++コンパイラに渡される拡張フラグ | CPPFLAGS | | Cプリプロセッサとそれを使うプログラムに渡される拡張フラグ | LDFLAGS | | コンパイラがリンカ(ld)を呼び出すときに渡される拡張フラグ |
パターンルールを使用して、新しい暗黙のルールを定義することもできます。パターンルールは、ターゲットと依存ファイルの一部に%を用いて記述します。%は、空でない任意の文字列に適合します。 例えば、Cプログラムのコンパイルを行う暗黙のルールとして、あえてデフォルト状態と同じものをパターンルールで記述すると、このようになります。 %.o : %.c
$(CC) -c $(CFLAGS) $(CPPFLAGS) $< -o $@ここで、$<や$@は自動変数と呼ばれる特殊な変数です。自動変数はルールが実行されるたびに、ターゲットと依存ファイルに基づいて設定される変数です。この例では$@はターゲットとなるオブジェクトファイル名に、$<は依存ソースファイル名に展開されます。 自動変数には、以下のようなものがあります。 表6.2 自動変数 | 自動変数 | 説明 |
|---|
$@ | ターゲットファイル名 | $< | 最初の依存ファイル名 | $? | ターゲットより新しいすべての依存ファイル名 | $^ | すべての依存ファイル名 |
変数は、makefileの外で定義することもできます。定義方法は2種類あります。 1つ目の方法は、makeコマンドの引数として指定する方法です。make 変数名=値とすることで、変数が定義されます。なお、makefile内に同じ名前の変数定義があった場合でも、こちらの引数による定義の方が優先(オーバーライド)されます。 2つ目の方法は、環境変数として指定する方法です。すべての環境変数は、makeの変数と同等に扱われます。しかし、こちらの変数定義はそれほど強いものではありません。make引数による定義や、makefile内の定義があった場合、そちらが優先(オーバーライド)されます。 ちなみに、makefile内で同じ変数を重複定義した場合、最後に定義されたものが優先(オーバーライド)されます。 オーバーライドが発生する例を見てみます。 | makefile内で定義した変数VARIABLEと環境変数SHELLを表示するだけのMakefile。 | | makeコマンドへの引数で定義した変数が、makefile内で定義した変数よりも優先されます。 | | makefile内で定義した変数が、環境変数よりも優先されます。 |
makefile内には、ある条件が成立したときだけ有効になる行を書くことができます。基本的な構文は以下のようになります。 CONDITIONAL-DIRECTIVE
TEXT-IF-TRUE
endif CONDITIONAL-DIRECTIVEの条件が真の時に、TEXT-IF-TRUEの行が有効になります。 また、else節を使って以下のように書くこともできます。 CONDITIONAL-DIRECTIVE
TEXT-IF-TRUE
else
TEXT-IF-FALSE
endif または CONDITIONAL-DIRECTIVE
TEXT-IF-ONE-IS-TRUE
else CONDITIONAL-DIRECTIVE
TEXT-IF-TRUE
else
TEXT-IF-FALSE
endif CONDITIONAL-DIRECTIVEは、ifeq、ifneq、ifdef、ifndefのいずれかの構文を使って記述します。 ifeqを使う場合、CONDITIONAL-DIRECTIVEは以下のようになります。 ifeq (ARG1, ARG2)
ifeq 'ARG1', 'ARG2'
ifeq "ARG1", "ARG2" どの書き方をしても意味は同じです。ARG1とARG2を展開し両者が等しい場合、真と判定されTEXT-IF-TRUEが有効になります。 ifneqもifeqと同様に記述することができますが、ARG1とARG2を展開し両者が等しくない場合、真と判定されTEXT-IF-TRUEが有効になります。 ifneq (ARG1, ARG2)
ifneq 'ARG1', 'ARG2'
ifneq "ARG1", "ARG2" ifdefは、指定された変数名の変数が定義済みの場合、真と判定されます。ifndefはその逆です。 ifdef VARIABLE-NAME
ifndef VARIABLE-NAME VARIABLE-NAMEに変数が指定された場合、変数を展開した後の文字列を変数名として使用します。 BAR = true
FOO = BAR
ifdef $(FOO)
BAZ = yes
endif とした場合、変数FOOは「BAR」に展開され、それが変数名として用いられます。変数BARは定義されているので、ifdef $(FOO)は真として判定され、BAZ = yes行が有効になります。 第1部「開発の基本的な流れ」の「make」で使用したmakefileがどのように動作しているのか、改めて見てみます。 図6.6「基本的なmakefile」では、Cソースファイルhello.cから実行ファイルhelloが生成されます。 | デフォルトでCROSSをarm-linux-gnueabiとして定義し、クロスコンパイルを行います。 | | CROSS変数が空でなければ、CROSS_PREFIXを定義します。 | | 暗黙のルールで使用される変数CCとCFLAGS、LDFLAGSを明示的に定義し、オーバーライドしています。これによって、gccの前にCROSS_PREFIXが付きます。 | | ファイル名が変わっても使いまわせるように、実行ファイルの名前を変数で定義します。 | | デフォルトゴール(一般的にallという名前を付けます)は、TARGETに依存します。 | | helloは、hello.oに依存します。 | | $@、$^は自動変数、CC、LDFLAGS、LDLIBSは暗黙のルールで使用される変数です。 | | cleanターゲットは、依存ファイルがないので必ず実行されます。 | | 生成したファイルや中間ファイルをすべて削除します。 | | Cプログラムのコンパイルを行うパターンルールを定義しています。 |
図6.6「基本的なmakefile」をMakefileという名前で保存し、Cソースコードをhello.cとして同じディレクトリに置いてからmakeすると、ARM (Armadillo)用の実行ファイルが生成されます。 [ATDE ~]$ make CROSS_COMPILE=arm-linux-gnueabi-
arm-linux-gnueabi-gcc -Wall -Wextra -O2 -c -o hello.o hello.c
arm-linux-gnueabi-gcc hello.o -o hello
[ATDE ~]$ file hello
hello: ELF 32-bit LSB executable, ARM, version 1 (SYSV), dynamically linked (uses shared libs), for
GNU/Linux 2.6.14, not stripped
make cleanで、生成されたすべてのファイルを削除できます。 [ATDE ~]$ ls
Makefile hello hello.c hello.o
[ATDE ~]$ make clean
rm -f *~ *.o
[ATDE ~]$ ls
Makefile hello.c
また、コマンドライン引数による変数定義を使ってmake CROSS=として変数CROSSをオーバーライドすると、ホストPC用の実行ファイルを生成できます。この例のようにすることで、同じmakefile、同じソースファイルから異なるアーキテクチャ用の実行ファイルを簡単に生成できるわけです。 [ATDE ~]$ make CROSS=
gcc -Wall -Wextra -O2 -c -o hello.o hello.c
gcc hello.o -o hello
[ATDE ~]$ ./hello
Hello World
図6.6「基本的なmakefile」では、1つのソースファイルから1つの実行ファイルを生成しています。これを、複数のソースから1つの実行ファイルを生成したり、複数の実行ファイルを生成するように変更してみます。 hello.cとworld.cから実行ファイルhelloが生成され、fiz.cとbaz.cから実行ファイルfizbazが生成されるようにする場合、このようになります。
実践的なプログラミングの話題に入る前に、C言語でプログラムを作成する際に気をつけるべきことについて復習しておきます。Linuxシステム独特の話題もありますので、他のOS上でのC言語プログラミングに慣れた方も確認してみてください。 6.2.1. コマンドライン引数の扱いと終了ステータス標準的なCプログラムでのmain関数は、以下のどちらかの形で定義しなければなりません。 int main(void);
int main(int argc, char *argv[]); 戻り値はint型として規定されています。引数は取らないか、またはargc,argvの2個を取ります[]。 Cソースをコンパイルして生成したプログラムをシェルから実行すると、自身のコマンド名と渡されたコマンドラインパラメータがmain関数の引数として渡ります。パラメータをつけずコマンド名のみで実行した場合はargcは1で、argvはコマンド名の文字列へのポインタです。パラメータをつけるとargcは(1+パラメータ数)となり、argvはコマンド名、パラメータ1、パラメータ2…といった形の文字列配列になります。 main関数の戻り値は、コマンドの終了ステータスになります。シェルの世界では0が真、0以外のすべての値を偽として扱いますので、プログラムが正常に終了した場合、main関数の戻り値は0であるべきです。 終了ステータスを表現するためのマクロが、ヘッダファイルstdlib.hで定義されています。正常終了、つまり0となる値としてEXIT_SUCCESSが、異常終了のための値としてEXIT_FAILUREが用意されています。本書のサンプルプログラムでは、終了ステータスとしてこれらを使用しています。 | その他の終了ステータス |
|---|
stdlib.hで定義されている終了ステータス以外の終了ステータスとしては、BSD由来のものがsysexits.hで定義されています。
|
プログラムの終了には、exit関数を呼ぶ方法もあります。 void exit(int status); このexit関数に渡すstatusが終了ステータスであり、main関数の戻り値と同様の扱いです[]。 main関数周りの動作を実際に見てみましょう。コマンドに渡したパラメータを順番に表示するプログラムです。 argv[0]にはコマンド名が格納されています。argv[1]以降は、与えたパラメータが順に格納されます。シェルからスペースを含む文字列をパラメータとして渡したい場合は、ダブルクォートかシングルクォートで囲みます。 シェルから呼ぶように作られたコマンドの多くは、「-」(ハイフン)始まりなどのオプション指定に対応しています。このようなオプションの解析を、すべて自前で実装するのはかなり手間のかかることです。これを楽にしてくれるライブラリ関数が存在します。 getopt関数は、「-」で始まるショートオプションの解析を助けてくれます。getopt_long関数は、「-」始まりのショートオプションと「--」始まりのロングオプションの両方を扱うことができます。ここではgetopt_longを使ってみます。 一見してわかるとおり、-nまたは--nameで指定した名前に対して挨拶を表示するプログラムです。-tまたは--timeで時刻を指定することができ、それによって挨拶文が変化します。-gまたは--germanを指定すると、挨拶文がドイツ語になります。 作成したコマンドに指定できるオプションを形式的に表記すると、次のようになります。 greeting <-n|--name NAME> [-t|--time TIME] [-g|--german] このプログラムのソースコードが、図6.11「greeting.c」です。 C言語を使用してプログラムを記述する際、プロセスを正常に終了する方法には、以下の3種類があります。 - main関数から戻る
- exit関数を呼ぶ
- _exit関数を呼ぶ
また、Linuxシステムで動作するプロセスは、正常に終了する方法以外に、シグナルを受けて終了する場合があります。 main関数から戻るか、exit関数によってプロセスが終了した場合、所定の終了処理が行われます。 まず、atexit関数やon_exit関数によって登録された関数が、それらが登録された順番とは逆順に呼ばれます。 次に、オープン中の標準入出力[]ストリームがすべてクローズされます。ストリームがクローズされると、バッファされている出力データはすべてフラッシュされ、ファイルに書き出されます。 また、tmpfile関数によって作成されたファイルは削除されます。 exit関数は、これらの処理を行ったあと、_exit関数を呼びます。 _exit関数内では、そのプロセスがオープンしたディスクリプタがすべてクローズされます。 さらに、Linuxシステムの場合、exitや_exit関数で行われる処理の他に、プロセス終了時にカーネルが資源の回収を行います。すなわち、プロセスがオープンしているすべてのディスクリプタをクローズし、使用していたメモリなどを開放します。 プロセスがシグナルを受信し、そのシグナルに対する動作がプロセスを終了させるものであった場合、プロセスは直ちに終了します。シグナルは、自プロセス以外のプロセスから送られることもありますし、プログラム中でabort関数やkill関数で自プロセスへシグナルを送ることもできます。 これらの終了処理やカーネルによる資源の回収処理があるため、アプリケーションプログラム内ではmallocしたメモリ領域は必ずfreeしなけばいけないということはありません。終了処理で行われることを把握した上で、資源の後始末を明示的にプログラム中に記述せず、それらに任せるという方法もあります。 C言語でプログラムを記述する際、エラー処理を怠りがちです。世にあるC言語プログラミングの参考書では、サンプルコードをシンプルに書くために、あえてエラー処理を書いていない場合が多いので、それらを参考にしてコードを記述すると、つい、エラー処理を忘れてしまいます。 しかし、実際に使用するプログラムでは、必ずエラー処理を行うコードを記述してください。特に組み込みシステムでは、PCやサーバーなどと比較して、振動や温湿度などの外部環境が厳しい環境で動作することが多いので、単純な処理でもエラーが発生することがあります。 システムコールまたはライブラリコールのエラーを検出する一般的な方法は、関数の戻り値をチェックすることです。システムコールといくつかのライブラリコールは、エラーが発生した場合errnoを設定します。errnoの値を確認することによって、エラーの発生要因を知ることができます。 システムコールやライブラリコールの戻り値や、それらが設定するerrnoの値は、manページで確認できます。 例えば、openシステムコールのmanページの返り値のセクションには、「open()とcreat()は新しいファイル・ディスクリプタを返す。エラーが発生した場合は-1を返す(その場合はerrnoが適切に設定される)。」と記述されています。また、エラーのセクションには、openシステムコールが返す可能性のあるerrnoの値と、どのような時に設定されるのかが記述されています。 システムコールのmanページをみるコマンドは、man 2 関数名です。ライブラリコールの場合は、man 3 関数名となります。manページの内容をよく確認し、エラーが発生した場合の処理を忘れずに記述してください。 エラー処理の例として、ファイルの内容を読み込み、標準出力に表示するプログラムのソースコードを図6.12「fdump.c」に示します。 このプログラムは、open、close、read、writeの4つのシステムコールを使用します。エラーが発生した際には、perror関数でerrnoに応じたエラーメッセージを表示します。 fdumpの実行結果を以下に示します。引数にファイル名を指定して実行すると、ファイルの内容を表示します。正常に終了したときの終了ステータスは0(EXIT_SUCCESS)になります。/var/log/messageは読み込み権限のないファイルなので、これを引数に指定してfdumpを実行すると、openシステムコールで失敗します。異常終了時には、エラーメッセージを表示して終了します。その時の終了コードは1(EXIT_FAILURE)になります。 次章からは、より実際に近いプログラムを目的別に取り上げていきます。 以降のプログラムでは、ソースコードを見やすくし、また何のエラーが起きたかを明確に可視化するために、エラー処理のための共通のヘッダファイルexitfail.hを使用することにします。 main関数を含んだソースでは、#defineマクロ定義でMAIN_Cを定義してこのヘッダをインクルードします。exitfail関数は、printf関数と同じ引数フォーマット形式で好きな内容のエラーメッセージを表示できます。exitfail_errnoは、ライブラリ関数の呼び出しでerrnoが更新されるタイプのエラー発生直後に呼び出す専用のものです。引数として渡した文字列(通常は関数名を想定しています)と、errnoを意味のある文章に変換したエラー文字列をセットで表示します。どちらの関数も、関数名どおりにexitしてEXIT_FAILUREを返します。 まずは、ファイルを扱う例です。一般的なCのテキストであっても最初の方で取り上げられるもので、基本的にはそれほど大きくは違いません。但し、PCのように高速だったり、ふんだんなメモリが積まれているわけではありませんから、無駄な処理をしないようにしたり、メモリリークを起こさないように一層の注意が必要といえます。 テキストファイルを扱うサンプルプログラムを紹介します。ここではComma Separated Values(CSV)ファイルと呼ばれる、データをカンマで区切った形式のものを扱ってみます。日本郵便が公開している住所の郵便番号(ローマ字)(CSV 形式)[]を処理する例としてみました。 以下のような仕様を満たすものとします。 - CSVファイルを中身を整形して表示するアプリケーション
- コマンド引数として、CSVファイル(郵便番号データ)を指定する
- 行頭にインデックス番号を表示し、その後スペース区切りで各項目を表示する
- 表示データが流れてしまわないように、画面サイズを超える場合は一時停止する
- 最後にデータ総数を表示する
郵便番号データCSVファイルの一行は、以下のように構成されています[]。 01101,"0600035","KITA5-JOHIGASHI","CHUO-KU SAPPORO-SHI","HOKKAIDO",0,0,1,0,0,0 先頭から順に、以下の内容を表しています。 全国地方公共団体コード,"郵便番号","町域名","市区町村名","都道府県名",フラグ1,フラグ2,フラグ3,フラ
グ4,フラグ5,フラグ6 フラグにはそれぞれ意味があるのですが、今回のプログラムに関して処理する必要のあるものは1つだけです。フラグ4が0であって同じ郵便番号が複数行続く場合は町域名が長いため複数行に分割されたデータとなる、という仕様です。 01224,"0660005","KYOWA(88-2.271-10.343-2.404-1.427-","CHITOSE-SHI","HOKKAIDO",1,0,0,0,0,0
01224,"0660005","3.431-12.443-6.608-2.641-8.814.842-","CHITOSE-SHI","HOKKAIDO",1,0,0,0,0,0
01224,"0660005","5.1137-3.1392.1657.1752-BANCHI)","CHITOSE-SHI","HOKKAIDO",1,0,0,0,0,0 この時は、複数行を一つのデータとして扱う対応を行うことにします。 ここまでの仕様に基づいたコードは、次のようになりました。 main関数から見ていきます。CSVファイルの操作は基本的に標準Cライブラリ関数で行っていますので、難しいところはないと思います。データはfgets関数で一行ずつ読み込み、strtok関数でカンマ区切りをトークン単位に分解。トークンがダブルクォートで始まっている場合は、これを外します。 ここのところでstrchrnulという、標準Cライブラリにない関数を使用しています。ダブルクォートを見つけるだけならstrchr関数でよいのですが、この関数は検索文字が見つからなかったときにNULLを返します。これを考慮すると p = strchr(++pbuf, '"');
if (p)
*p = '\0';のように処理しなくてはなりません。 ここでman strchrとすると、似たような関数として以下のような説明が見つけられます。 SYNOPSIS
#define _GNU_SOURCE
#include <string.h>
char *strchrnul(const char *s, int c);
DESCRIPTION
The strchrnul() function is like strchr() except that if c is not found
in s, then it returns a pointer to the null byte at the end of s,
rather than NULL.strchrnul関数は、(strchrとは違い)未発見時に終端文字'\0'位置へのポインタを返します。このためサンプルプログラムのように条件分岐が不要になります。なお上記manに説明されていますが、こうしたGNU拡張関数を使う場合はヘッダ(今回の場合string.h)インクルード前にGNU拡張関数を使うためGNU_SOURCEマクロを定義(#define)しておく必要があります。今回は小さな例ですが、このようにmanには便利な情報が多く記載されており大変有用です。 トークン解析処理が終わると、これを数値変換や文字列コピーして保持します。前述した複数行にわたる長い町域名に対応するため、複数回のループにまたがって一つのデータを処理することがあります。 こうして完成した一つのデータを表示しているのは、printline関数です。この関数では、データをsnprintfで読みやすい形の文字列に整形しています。大量の表示データが流れていってしまわないように、画面サイズ(マクロ定義で横60文字×縦17文字とされています)ごとに一時停止する処理を入れつつ、表示を行います。また、最後に行われるデータ総数表示にもこの関数を使用(引数pcsvlineにNULLを指定)しますので、このための分岐処理も入れてあります。 作成したアプリケーションdispcsv1にCSVファイル名を渡すと、データが整形表示されます。 リターンを入力すると次に進みます。途中で終了したいときは、Ctrl+Cを入力してください。 アプリケーションの設定を保存するとき、.iniや.confといった設定ファイルを用いることがあります。設定ファイルも普通はテキストファイルですので標準Cライブラリ関数を駆使して作成することができますが、こうした目的のために特別な機能が用意されたライブラリを使うと、短いコードで効率的に扱うことが可能です。ここではGLibというライブラリを使ってconfファイルを使用する例を紹介します。 以下のような機能を加えてみます。 dispcsv2.confファイルを参照して、動作の設定を可能にする- 表示一時停止判定用の画面サイズを設定できるようにする
- 表示一時停止を行うかどうか設定できるようにする
- データ総数の表示を行うかどうか設定できるようにする
- 各データの条件を設定して一致/部分一致したもののみを表示できるようにする
- 文字列の条件比較においては大文字小文字を同一視する
dispcsv2.confファイルが存在しない場合、初期状態が設定されたconfファイルを自動作成する
サンプルプログラムは、先ほど作ったものに手を加えたものです。機能実装のために追加したコードがほとんどで、大きく構造を変更はしていません。 #define _GNU_SOURCE /* strchrnul関数使用のために必要 */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <glib.h>
#define MAIN_C
#include "exitfail.h"
/* 表示する文字数 */
#define DISP_WIDTH 60 /* 幅 */
#define DISP_HEIGHT 17 /* 高さ */
/* CSVデータ各要素のサイズ */
#define ZIPCODE_LEN 8
#define STREET_LEN 512
#define CITY_LEN 64
#define PREF_LEN 16
#define FLAG_NUM 6
/* CSVデータ1行の要素数 */
#define COLUMN_NUM (5 + FLAG_NUM)
/* CSVデータ構造体 */
typedef struct {
long code; /* 全国地方公共団体コード */
char zipcode[ZIPCODE_LEN]; /* 郵便番号 */
char street[STREET_LEN]; /* 町域名 */
char city[CITY_LEN]; /* 市区町村名 */
char pref[PREF_LEN]; /* 都道府県名 */
long flag[FLAG_NUM]; /* フラグ配列 */
} csvline_t;
#define BASENAME(p) ((strrchr((p), '/') ? : ((p) - 1)) + 1)
/* conf設定ファイル内で使用するキーワードの定義 */
#define GROUP_DISPLAY "dispaly"
#define KEY_WIDTH "Width"
#define KEY_HEIGHT "Height"
#define GROUP_CONTROL "control"
#define KEY_PAUSE "Pause"
#define KEY_COUNT "Count"
#define GROUP_DATA "data"
#define KEY_CODE "Code"
#define KEY_ZIPCODE "Zipcode"
#define KEY_STREET "Street"
#define KEY_CITY "City"
#define KEY_PREF "Pref"
#define KEY_FLAG "Flag"
/* conf設定保持用構造体 */
typedef struct {
struct { /* 表示設定グループ */
gint width; /* 表示幅 */
gint height; /* 表示高さ */
} display;
struct { /* 制御設定グループ */
gboolean pause; /* 一時停止の有無 */
gboolean count; /* 総数表示の有無 */
} control;
struct { /* データ条件設定グループ */
gint code; /* 全国地方公共団体コード */
gchar *zipcode; /* 郵便番号(部分一致) */
gchar *street; /* 町域名(部分一致) */
gchar *city; /* 市区町村名(部分一致) */
gchar *pref; /* 都道府県名(部分一致) */
gint *flag; /* フラグ配列 */
gsize flag_len; /* フラグ配列要素数 */
} data;
} config_t;
/* conf設定保持用領域ポインタ */
static config_t *pconf;
/**
* confファイル読み込み関数
* @param conffilename confファイル名
*/
static void readconf(char conffilename[])
{
GKeyFile *keyfile;
GError *error = NULL;
gint flag[FLAG_NUM];
gsize len;
gchar *pdata;
FILE *pconffile;
int i;
/* conf設定保持用領域確保 */
pconf = g_slice_new(config_t);
/* キーファイル確保 */
keyfile = g_key_file_new();
/* confからキーファイル読み込み、失敗した場合は新規作成 */
if (!g_key_file_load_from_file(keyfile, conffilename,
G_KEY_FILE_KEEP_COMMENTS |
G_KEY_FILE_KEEP_TRANSLATIONS,
&error)) {
/* デフォルト設定 */
pconf->display.width = DISP_WIDTH;
pconf->display.height = DISP_HEIGHT;
pconf->control.pause = TRUE;
pconf->control.count = TRUE;
pconf->data.code = -1;
pconf->data.zipcode = "";
pconf->data.street = "";
pconf->data.city = "";
pconf->data.pref = "";
for (i = 0; i < FLAG_NUM; i++)
flag[i] = -1;
pconf->data.flag = flag;
pconf->data.flag_len = FLAG_NUM;
/* キーファイル書き込み */
g_key_file_set_integer(keyfile, GROUP_DISPLAY, KEY_WIDTH,
pconf->display.width);
g_key_file_set_integer(keyfile, GROUP_DISPLAY, KEY_HEIGHT,
pconf->display.height);
g_key_file_set_boolean(keyfile, GROUP_CONTROL, KEY_PAUSE,
pconf->control.pause);
g_key_file_set_boolean(keyfile, GROUP_CONTROL, KEY_COUNT,
pconf->control.count);
g_key_file_set_integer(keyfile, GROUP_DATA, KEY_CODE,
pconf->data.code);
g_key_file_set_string(keyfile, GROUP_DATA, KEY_ZIPCODE,
pconf->data.zipcode);
g_key_file_set_string(keyfile, GROUP_DATA, KEY_STREET,
pconf->data.zipcode);
g_key_file_set_string(keyfile, GROUP_DATA, KEY_CITY,
pconf->data.city);
g_key_file_set_string(keyfile, GROUP_DATA, KEY_PREF,
pconf->data.pref);
g_key_file_set_integer_list(keyfile, GROUP_DATA, KEY_FLAG,
pconf->data.flag,
pconf->data.flag_len);
/* キーファイルからテキストデータ取得 */
pdata = g_key_file_to_data(keyfile, &len, &error);
if (!pdata)
g_error(error->message);
/* 新規ファイルを作成してテキストデータ書き込み */
pconffile = fopen(conffilename, "w");
if (!pconffile)
exitfail_errno("fopen");
if (fwrite(pdata, len, 1, pconffile) < 1)
exitfail_errno("fwrite");
fclose(pconffile);
}
/* conf読み込みに成功した場合、設定を保持 */
else {
pconf->display.width =
g_key_file_get_integer(keyfile, GROUP_DISPLAY,
KEY_WIDTH, NULL);
pconf->display.height =
g_key_file_get_integer(keyfile, GROUP_DISPLAY,
KEY_HEIGHT, NULL);
pconf->control.pause =
g_key_file_get_boolean(keyfile, GROUP_CONTROL,
KEY_PAUSE, NULL);
pconf->control.count =
g_key_file_get_boolean(keyfile, GROUP_CONTROL,
KEY_COUNT, NULL);
pconf->data.code =
g_key_file_get_integer(keyfile, GROUP_DATA,
KEY_CODE, NULL);
pconf->data.zipcode =
g_key_file_get_string(keyfile, GROUP_DATA,
KEY_ZIPCODE, NULL);
pconf->data.street =
g_key_file_get_string(keyfile, GROUP_DATA,
KEY_STREET, NULL);
pconf->data.city =
g_key_file_get_string(keyfile, GROUP_DATA,
KEY_CITY, NULL);
pconf->data.pref =
g_key_file_get_string(keyfile, GROUP_DATA,
KEY_PREF, NULL);
pconf->data.flag =
g_key_file_get_integer_list(keyfile, GROUP_DATA,
KEY_FLAG,
&pconf->data.flag_len,
NULL);
}
/* キーファイル開放 */
g_key_file_free(keyfile);
}
/**
* 行表示関数
* @param pcsvline 表示するCSVデータ構造体へのポインタ(NULLの場合は表示済データの総数を表示)
*/
static void printline(csvline_t *pcsvline)
{
static int count = 0; /* 表示したデータ総数 */
static int line = 0; /* 一画面中に表示した行数 */
int disp_width = DISP_WIDTH, disp_height = DISP_HEIGHT, newline;
char buf[1024];
unsigned int i;
/* CSVデータの各要素を表示 */
if (pcsvline) {
/* 郵便番号が入っていない場合は表示しない */
if (!pcsvline->zipcode[0])
return;
/* 全国地方公共団体コード条件設定があり、一致しなかったら表示しない */
if (pconf->data.code >= 0 && pcsvline->code != pconf->data.code)
return;
/* 郵便番号条件設定があり、部分一致しなかったら表示しない */
if (pconf->data.zipcode[0] != '\0' &&
!strcasestr(pcsvline->zipcode, pconf->data.zipcode))
return;
/* 町域名条件設定があり、部分一致しなかったら表示しない */
if (pconf->data.street[0] != '\0' &&
!strcasestr(pcsvline->street, pconf->data.street))
return;
/* 市区町村名条件設定があり、部分一致しなかったら表示しない */
if (pconf->data.city[0] != '\0' &&
!strcasestr(pcsvline->city, pconf->data.city))
return;
/* 都道府県条件設定があり、部分一致しなかったら表示しない */
if (pconf->data.pref[0] != '\0' &&
!strcasestr(pcsvline->pref, pconf->data.pref))
return;
for (i = 0; i < FLAG_NUM && i < pconf->data.flag_len; i++) {
/* フラグ条件設定があり、一致しなかったら表示しない */
if (pconf->data.flag[i] >= 0 &&
pcsvline->flag[i] != pconf->data.flag[i])
return;
}
/* 各要素を表示フォーマットに展開 */
snprintf(buf, sizeof(buf),
"%6d %05ld %s %s %s %s %ld %ld %ld %ld %ld %ld",
count++, pcsvline->code, pcsvline->zipcode,
pcsvline->street, pcsvline->city, pcsvline->pref,
pcsvline->flag[0], pcsvline->flag[1],
pcsvline->flag[2], pcsvline->flag[3],
pcsvline->flag[4], pcsvline->flag[5]);
}
/* CSVデータの総数を表示 */
else {
/* 総数表示無効なら表示しない */
if (!pconf->control.count)
return;
/* データ総数を表示フォーマットに展開 */
sprintf(buf, "Count: %6d", count);
}
/* 今回追加される表示行数を計算 */
disp_width = pconf->display.width;
disp_height = pconf->display.height;
newline = (strlen(buf) + (disp_width - 1)) / disp_width;
/* 1画面を超える場合、入力があるまで一時停止 */
if (line + newline >= disp_height) {
/* 一時停止有効なら */
if (pconf->control.pause)
getchar();
/* 表示行数を初期化 */
line = 0;
}
/* 実際に表示する */
printf("%s\n", buf);
/* 表示行数を更新 */
line += newline;
}
/**
* main関数
* @param argc 引数なしの場合はusage表示のみ
* @param argv 第1引数として読み込みCSVファイル名を指定
* @return exit値
*/
int main(int argc, char *argv[])
{
FILE *pcsvfile; /* CSVファイルポインタ */
csvline_t csvline; /* CSVデータ */
char buf[256], *pbuf, *pcol[COLUMN_NUM];
int i;
exitfail_init();
/* 引数が指定されなかった場合、usage表示して終了 */
if (argc < 2) {
printf("Usage: %s <csvfile>\n", BASENAME(argv[0]));
return EXIT_SUCCESS;
}
/* confファイル名を作成 */
snprintf(buf, sizeof(buf), "%s.conf", argv[0]);
/* confファイルを読み込み */
readconf(buf);
/* CSVファイルオープン */
pcsvfile = fopen(argv[1], "r");
if (!pcsvfile)
exitfail_errno("fopen");
/* CSVデータを初期化 */
memset(&csvline, 0, sizeof(csvline));
/* CSVファイルから1行読み込む */
while (fgets(buf, sizeof(buf), pcsvfile)) {
/* 各要素へのポインタ配列を初期化 */
memset(pcol, 0, sizeof(pcol));
/* 次のカンマ(または行末)を見つけてトークン化 */
pbuf = strtok(buf, ",\n");
for (i = 0; i < COLUMN_NUM && pbuf; i++) {
/* 前後のダブルクォートは除去する */
if (*pbuf == '"')
*strchrnul(++pbuf, '"') = '\0';
/* 要素へのポインタを保持 */
pcol[i] = pbuf;
/* 次のカンマ(または行末)を見つけてトークン化 */
pbuf = strtok(NULL, ",\n");
}
/* 要素数が不足している場合、次行にスキップ */
if (i < COLUMN_NUM)
continue;
/* 新しいデータの場合 */
if (strcmp(pcol[1], csvline.zipcode) ||
strtol(pcol[8], NULL, 10)) {
/* 保持済みのデータを表示 */
printline(&csvline);
/* CSVデータ各要素を保持 */
memset(&csvline, 0, sizeof(csvline));
csvline.code = strtol(pcol[0], NULL, 10);
strncpy(csvline.zipcode, pcol[1],
sizeof(csvline.zipcode) - 1);
strncpy(csvline.street, pcol[2],
sizeof(csvline.street) - 1);
strncpy(csvline.city, pcol[3],
sizeof(csvline.city) - 1);
strncpy(csvline.pref, pcol[4],
sizeof(csvline.pref) - 1);
for (i = 0; i < FLAG_NUM; i++)
csvline.flag[i] = strtol(pcol[5 + i], NULL, 10);
}
/* 既存データへの追加の場合 */
else
/* 町域名の続きを追加 */
strncat(csvline.street, pcol[2],
(sizeof(csvline.street) -
strlen(csvline.street)) - 1);
}
/* 保持済みのデータを表示 */
printline(&csvline);
/* CSVファイルクローズ */
fclose(pcsvfile);
/* データ総数を表示 */
printline(NULL);
return EXIT_SUCCESS;
}図6.17 CSVファイルの内容を表示するプログラムのconfファイル対応版 (dispcsv2.c) GLibの詳細なAPI説明については、以下のURLや市販の書籍などを参照してください。 GLib Reference Manual ここでは簡単に流れを説明するに留めます。main関数から見ていくと、冒頭でconfファイル名を作成してからreadconf関数を呼んでおり、この中でconfファイルから設定を読み込んでいます。 readconf関数ではまず必要なメモリ領域を確保し、g_key_file_load_from_file関数でconfファイルを読み込みます。この戻り値で0が返って来たときはファイルがなかったものとしてデフォルト設定を使用し、g_key_file_to_dataでテキストデータに変換してから新規confファイルとして書き込みます。 confファイルが読み込めたときは、pconfから示される領域に各設定を保持します。このGLibのconfファイルは、グループによって分類されるキーに対して各値が設定される形式になっています。例えば一つ目の項目の場合、グループdisplayのキーWidthについて1つの数値が設定されています。その後の項目のように1つの文字列や真偽値、複数の数値・文字列を設定するキーを作成することも可能です。 読み込まれ保持した設定は、printline関数内で表示の制御に使用しています。ここは事前に決めた仕様どおりに動作を変更しているだけですから、コード内容を見てください。 GLibを使う時は、makefileにも注意する必要があります。GLib用のヘッダファイルやライブラリファイルは、標準Cライブラリ向けのものとは違う特別なディレクトリに配置されるため、これをgccに教えてあげなくてはならないのです。それらがどこにあるかわかれば、適切にmakefileに設定してgccに渡るようにすれば良いのですが、ATDEにも入っているpkg-configというツールを使ってこれを簡略化できます。 指定されたCROSS(=アーキテクチャ名)からPKGCONFIG_LIBDIRを作っています。これが、目的のクロス環境pkgconfig情報があるパスになります。このPKGCONFIG_LIBDIRが定義された状態でpkg-configコマンドを実行すると、CFLAGS用のオプション(-I<dir>のヘッダファイルパス)や、LIBS(ライブラリ名)を教えてくれるのです。こうしてGLibを使う場合も、それなりにシンプルにmakefileを書くことができます。 これを使ってmakeし、プログラムを実行してみます。 1回目の動作は先ほどのものとまったく変わりませんが、Ctrl+Cで終了するとdispcsv2.confファイルができています。 [dispaly]
Width=60
Height=17
[control]
Pause=true
Count=true
[data]
Code=-1
Zipcode=
Street=
City=
Pref=
Flag=-1;-1;-1;-1;-1;-1; 角括弧で囲われた単語がグループ、その下にイコール記号を使って値が設定されている単語がキーになります。以下のように動作を変更させてみます。 - 画面サイズは80x24
- 一時停止しない
- 町域名にKOKUBUNJIを含んだもののみ出力する
[dispaly]
Width=80
Height=24
[control]
Pause=false
Count=true
[data]
Code=-1
Zipcode=
Street=kokubunji
City=
Pref=
Flag=-1;-1;-1;-1;-1;-1; テキストエディタでこのようにdispcsv2.confを変更して実行すると、以下のように動作します。 バイナリファイルを扱う例として、Windowsで使われるBMP形式の画像ファイルを表示してみます。とはいっても、グラフィック画面は使用しません。コンソール上のみで実行できるように、エスケープシーケンスを使用したカラー対応のアスキーアート(文字を使った擬似画像)表示サンプルプログラムです。 bitmap.hは、BMPファイル形式のヘッダを解析するための構造体を定義したヘッダファイルです。dispbmp.cのmain関数と平行して、見ていきます。
main関数は、まず引数で指定されたbmpファイルをオープンし、そしてBITMAPFILEHEADER構造体分のデータを読み込んでヘッダの中身を解析していきます。まずはTYPEが正しくBMであることから順次チェックしていくのですが、2番目の要素であるSIZEの読み込みで少々困ったことになります。 BITMAPFILEHEADER構造体の先頭の要素であるbfTypeが2バイトであり、次のbfSizeが4バイトであるため、構造体メンバとして直接参照しようとするとアドレス2から4バイト参照することになり、ARMアーキテクチャでは正しく値を読むことができません。このため、このサンプルではbfSizeメンバを4バイトとして直接定義せず、bfSize_l/bfSize_hと上位下位2バイトずつのメンバとして分断させ、別々に読み込んだものを一つの4バイトとして扱うためのサポートマクロBITMAPFILEHEADER_SIZEを用意する方法を取りました。こうすることで、呼び出し側は分断されたデータであることを意識することなく、要素の比較ができます。 ヘッダ2種類の解析の後、その情報に基づいた形で画像データを読み込んでいきます。アスキーアート化するため、いくつかの並んだ画素を一つとしてRGB別に配列に蓄えていき、この値の大きさで出力する色を決定します。色付けの決定方法は、ここでは本筋から外れますので省略します。 最終段の出力は、printfで行っています。色付けはエスケープシーケンスという手法を用いており、0x1bに相当するコントロールコードの後に前景/背景と色を指定するための情報を付加して出力します。 サンプルBMPファイルのmadillon.bmpを指定して実行すると、以下のように出力されます。 [armadillo ~]$ ./dispbmp midomadillo.bmp
「ファイルの種類」で説明したように、Linuxシステムを含むUNIXシステムでは、すべてをファイルとして表現します。 Armadilloというハードウェアが持つ、シリアルインターフェースやGPIO、LED、スイッチなどのデバイスも例外ではありません。Linuxカーネルは、これらのデバイスをファイルとして扱えるように抽象化します。 本章では、このようなファイルを扱う方法について説明します。 デバイスを抽象化したファイルで最も一般的なものは、デバイスファイル[]です。 デバイスファイルには、キャラクタデバイスとブロックデバイスの2種類があります。それぞれの特徴は、「ファイルの種類」を参照してください。 デバイスファイルは、通常、/devディレクトリ以下にあります。ls -lを実行したときに、一番左に表示される文字がcのファイルがキャラクタデバイスで、bがブロックデバイスです。 デバイスファイルをC言語で扱うには、通常ファイルと同様に、open、close、read、writeシステムコールを使用します。 また、デバイスファイル特有のシステムコールとして、ioctlがあります。ioctlでは、デバイスのパラメータを変更するなど、通常のread/write操作とは馴染まないデバイスへの操作を行うために使用されます。ioctlの使い方は、対象となるデバイスによって異なります。 デバイスファイルを扱う例は、「シリアルポートの入出力」で説明します。 sysfsファイルシステムは、procファイルシステムに似た特殊ファイルシステムです。ユーザーランドアプリケーションは、sysfsファイルシステムを通して、カーネル内部のデータ構造にアクセスできます。sysfsファイルシステムが提供するファイルのいくつかは、物理的なデバイスに対応しており、それらに対して読み書きすることで、デバイスを制御することができます。 sysfsファイルシステムは、通常、/sysディレクトリにマウントします。 sysfsを扱う例として、LEDの制御について説明します。 LEDは、LinuxシステムではLEDクラスとして汎用化されています。LEDクラスとして登録されたLEDに対する操作は、/sys/class/leds/以下のディレクトリによって行います。/sys/class/leds/(LED名)/brightnessという名前のファイルに対して、0という文字を書き込むとLEDが消灯します。また、1を書き込むと点灯します。詳しい仕様は「Armadillo-400シリーズソフトウェアマニュアル」の「8. Linuxカーネルデバイスドライバー仕様/8.10.LED」を参照してください。 Armadillo-400シリーズでは、red、green、yellowの3個のLEDをLEDクラスとして扱えます。 シェルからLEDを点灯/消灯する例を、以下に示します。 | red LED を点灯します | | red LED を消灯します |
C言語でのsysfsファイルシステムのファイルの扱いは、通常ファイルと同じです。LEDを扱う簡単な例を、図6.25「LEDの点灯/消灯を行うプログラム(led_on_off.c)」に示します。 | red LED を点灯します | | red LED を消灯します | | green LED を点灯します | | green LED を消灯します |
シリアルポートで入出力を行うプログラムを作ってみます。 Linuxでは、テキストデータを扱うコンソール端末用として、行単位に文字を扱ったり自動的に変換したりしたりしてくれるカノニカルモードがあるのですが、意図したデータをそのまま転送したい場合には不都合です。バイナリデータも自由に扱えるようにするには非カノニカルモードに設定する必要があります。ここでは非カノニカルモードを使います。 シリアルポートから受け取ったデータをそのまま返してくれる、エコーサーバーを作ってみます。 - 9600bpsで接続する。
- 8bitデータ、パリティなし、フロー制御なし
まずはこの条件だけの、シンプルなものにします。 ポイントがいくつかあります。まず先に、シリアルポートの設定を行っているところを見てみます。setup_serial関数がそれですが、ここでstruct termios構造体tioのメンバに対して値を書き込んでいるところが重要です。c_iflagやc_cflagに対して、8bit/パリティなし/フロー制御なしであること、また非カノニカルモードにすることを意識して、適切な値を書かなければなりません。ボーレートの設定については、それらとは別にcfsetspeed関数を使います。 tcsetattr関数で、作成したtio状態を実際にシリアルデバイスに反映させるのですが、ここで1点重要なことがあります。この設定はこのプログラム内のみならずシステム全体に影響してしまうものであり、プログラムが正常に終了したり、また不正な終了や(Ctrl+C入力によるような)強制終了が発生した場合、初期状態に戻ってはくれません。つまり、行儀よくバグの少ないコードを書こうとするならば、どのような終了時であっても初期状態に戻してあげるような注意が必要なのです。 このプログラムでは、atexit関数とシグナルハンドラを使ってこれを実現しています。setup_serial関数内で呼ばれているatexit関数は、exitされる時(main関数からのreturn時も含みます)に呼ばれて欲しいハンドラ関数を登録するためのものです。これを使ってrestore_serial関数が登録されていますので、終了時には必ずシリアルポート設定の状態が復帰されます。また、いくつかの不正/強制終了に対応するために、set_sig_handleでシグナルハンドラを登録しています。 もう1つのポイントは、read/write関数のエラー処理でしょう。これらの関数は、シグナルが発生された時に中断して、戻り値-1となることがあります。このプログラムの目的としては、これを致命的なエラーとして扱うのは適切ではありません。このため、errnoがEINT(シグナル発生による中断を表す)であった場合はcontinueしてリトライするような作りにしています。なお、この際にCtrl+Cによる中断シグナル(SIGINT)などであった場合には、グローバル変数terminatedをチェックしてきちんとループを抜けるようにしてあります。 空いている(現在コンソールとして使っていない)シリアルポートと、PCの空いているシリアルポート(もちろんUSBシリアルデバイスでも構いません)をクロスケーブルで接続し、PC側ではTera Termを立ち上げます。ここでの設定は、プログラムに合わせ9600bps/8bit/パリティなし/フロー制御なしとします。 この状態で、シリアルポート名を引数として図6.28「serial_echo_server1の実行例」を実行します。 Tera Termから入力した文字が、そのまま返ってくるのが確認できます。 先ほどのシリアルエコーサーバーをWindows版Tera Termで試すと、改行した際に次の行に行かず、現在入力している行の先頭から上書きされるような状態になってしまいます。これは、LinuxとWindowsで改行を表すコードが異なるためです。 Linuxでは、改行コードとしてLF(ラインフィード)、バイナリで表すと0x0a[]を使用します。これに対し、Windowsでは改行コードとしてCR(キャリッジリターン)+LF、バイナリで表すと0x0d[], 0x0aという連続2文字を使用します。さらにTera Termのデフォルトの状態は、改行コードとしてCRの1文字のみを送出する状態になっています[]。 先ほどのプログラムをちょっと改造して、この違いを吸収してみましょう。 大きく追加された箇所は、main関数後半のwhileループ内です。CRを受け取り、その次がLFでなかった場合はLFを補ってあげることで、Windows上でも改行状態として見えるように改変するロジックが入っています。 なお、このLF挿入処理が発生した場合は、データサイズが大きくなっていく(最大で元データの2倍)ことになるため、READ_SIZEを定義してread時点ではバッファの半分までしか使用しないように変更しています。 ここまでのプログラムは、readしたものを一旦バッファに蓄えてから、必ずバッファ内のすべてをwriteして、またreadするというシンプルなつくりでした。受信と送信が等速であるような理想的な環境であればこれでも構いませんが、接続相手や機器仕様によってはそう決め付けられないことも多く、その場合はこの手順は効率的とは言えません。 これを改善するためのアプローチとして、複数のプロセスを動作させて送受信を平行動作させる方法もありますが、今回のようなケースでは中間となるバッファの扱い方に工夫を凝らさなければならず、大げさとも言えます。 整理してみると、解決したい問題となるのは以下のような状況です。 - 送信に時間がかかり待たされる状態なのに、次の受信データが来てしまっている。
- 送信ができないので受信待ち状態に入ったら、送信の方が先にできるようになった。
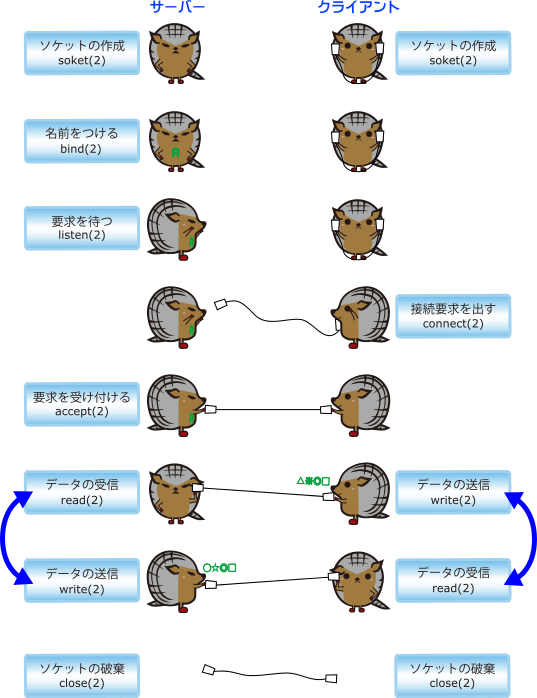
どちらも待ち状態に入ってしまい、融通が利かなくなってしまうことが問題点です。であれば、送受信ができない状態になったら即座に中断し、先に可能になったものから優先的に処理するというアプローチであれば解決できそうです。selectというシステムコールを使用して、このような実装が可能です。 main関数後半部分のwhileループ内の構造が、やや大きく変わりました。まず、送受信の可能な条件を考えてみます。受信はバッファが一杯の時はできず、送信はバッファにデータがない時はできません。これを加味して、select関数に適切な引数を渡します。 select関数は、fd_set型で指定されたデバイスに対して、送信・受信ができるようになるまで待ってくれます。プログラム内で、変数prdfdsとしているもので受信側、変数pwrfdsとしているもので送信側、それぞれに入っているデバイス群を監視します。 送受信どちら側(あるいは両方)が空いたかについては、FD_ISSETというマクロで渡したfd_setの変化をチェックすることで判定できます。なお、select関数もreadやwriteと同様、シグナルにより中断して-1を返すことがある点についても注意してください。 実行結果は、見た目上は先ほど作ったものと変わりありません。しかしながら、こちらの方がより効率的であり、構造的にもわかりやすく見えるのではないかと思います。 LinuxなどのUNIX系OSでは、ネットワーク通信を行なうためにソケットという概念を用いた仕組みを使います。ソケットはファイルと同じように扱うことができるので、シリアルポートの時と同様にreadやwriteといった関数でデータ送受信を行なうことができます。 Ethernet上で単純にネットワーク通信を行うと、送信したデータの紛失、化け、到達順番の入れ替わりなどが発生する可能性があります。TCP/IPはこれらの問題を吸収し、信頼性の高い通信を提供するためのプロトコルです。例えばデータが紛失した場合、データの再送を行うことで信頼性を確保します。TCP/IPは高い信頼性が必要なネットワーク通信で標準的に使われており、HTTPやFTPなど多くのネットワーク通信プロトコルの基盤となっています。 TCP/IPでの通信手順を模式化すると、次の図のようになります。サーバーとクライアントは、通信を行なう前に通信経路を確立する必要があります。 通信経路を糸電話に例えると、次のようになります。 - 糸電話で話をする人(ソケット)を作成する
- サーバーは、クライアントから糸電話を投げてもらう場所を指定する(名前を付ける)
- サーバーは、投げてもらうまで待つ(要求を待つ)
- クライアントはサーバーに糸電話を投げる(接続要求を出す)
- サーバーは糸電話を受け取る(要求を受け付ける)
- 話をする(データの送信/受信)
- 話が終わったら糸電話で話をした人は帰る(ソケットの破棄)
ソケットとTCP/IPを使って、簡単なサーバーアプリケーションを作ってみます。まずはこんな仕様にしてみます。 - サーバーが接続を待つポートは、コマンドライン引数で指定する。
- クライアントからはtelnetアプリケーションで接続でき、接続するとHello!と表示される。
こんなプログラムになります。 ソケットは2つ作られます。1つ目は、クライアントからの接続を待つためのソケットです。こちらはsocket関数で作成し、sockaddr_in型の変数server_addrに接続待ちするポートを入れてbind、それからlisten関数で接続を待つ動作に入ります。 クライアントから接続があると、accept関数で新たに入出力用のソケットが作られます。プログラムの作り方次第では複数のクライアントを待つこともできるのですが、このサーバーは1接続のみとしますので、ここで接続待ち用のソケットは破棄してしまっています。 入出力用のソケットができてしまえば、後はシリアルポートの時と同じようにread/writeできます。ここではHello!メッセージだけ表示して、ソケットを閉じてプログラムを終了しています。 Armadillo上でこのネットワークサーバーを動作させます。この例では、ポートは65432を指定してみました。 PCからtelnetで接続してみます。ATDE上からでも、WindowsのDOSプロンプトなどからでも構いません。接続コマンドは同じです。telnetのパラメータとして、サーバー(Armadillo)のIPアドレス(ここでは例として、192.168.1.100であるとします)と接続ポートを指定します。 このようにHello!と表示されてから、すぐに切断されます。 | ソケットの再利用 |
|---|
同じポートの指定でnetwork_hello_serverを何度も実行すると、エラーメッセージが表示されて起動できないことがあります。 [armadillo ~]$ ./network_hello_server 65432
./network_hello_server: bind: Address already in use
bindしようとしたアドレスが使用中です、というエラーメッセージです。サーバーの終了時に、ソケットはクローズしているのに…これは、TCP/IPを使用していることに起因しています。 TCP/IPは送信データの到達を保証するものであるため、データが紛失した際は再送しなければなりません。このプログラムのように、送信後すぐにソケットをクローズしてしまった場合であっても、その後に再送する可能性があるため、システムはしばらく(2~4分程度)ソケットを破棄しないまま保持し続けます。このようなソケットを、TIME_WAIT状態であるといいます。なお、(接続しに行った側である)クライアントが先にソケットをクローズした場合は、TIME_WAIT状態にはなりません。 |
Hello!を改造して、シリアルポート送受信で作成したエコーサーバーのネットワーク版を作成してみます。 ソースに追加されたselect, read, writeを使う入出力部の基本構造は、シリアルポートの時とまったく一緒です。 先ほどと同じようにサーバーを実行してみます。 PCからtelnetで接続してみます。 先ほどと違い、Hello!が表示された後にソケットがクローズされません。その後はエコーサーバーですので、入力したものがそのまま返ってきます。 telnet実行直後に表示されているように、Ctrlキーを押しながら]キーを押すとエスケープすることができます。「telnet> 」というプロンプトが表示されるので、quitと入力してtelnetコマンドを終了することができます[]。 このように動作するのはATDEからtelnetした場合です。実は、他のtelnetアプリケーションから接続した場合、それぞれちょっとずつ動作が違ってきてしまいます。 例えばWindowsのDOSプロンプトからtelnetコマンドで接続した時は、以下のようになりました[]。 このように、1文字打つたびに文字が返ってきています。 これは、単純にtelnetクライアントアプリケーションの挙動が違うだけです。ATDE (つまりLinux)のtelnetクライアントは(改行が入力されるたびに)行単位でデータを送信し、Windowsのtelnetクライアントは1文字入力するたびにデータを送信しているということになります。 また、Tera Termにもtelnet機能があります。こちらの場合は(標準の設定では)打ち込んだものがそのまま表示はされません。これは設定の問題なので良いのですが、シリアルエコーサーバーの時と同じように、CRやLFの改行コードの違いによる問題も発生します。 WindowsのtelnetやTera Term相手の時も、Linuxのtelnetの時と同じように表示するようにサーバーアプリケーションを改造してみます。 Windows用telnet対応のための変更点は1点だけ。write可能を待つかどうか判定する際に、memchr関数によるデータ内容の確認を行っています。改行文字が来るまでは、writeされないようにしているわけです。 そして、Tera Termのtelnetでの改行文字問題の修正ですが、これはシリアルエコーサーバーでの図6.30「改行コード変換を行うシリアルエコーサーバー(serial_echo_server3.c)」の対策とまったく一緒です。 同じtelnetアプリケーションとはいえ、このように(見た目の)動作に差が出ることもあります。より汎用的で完成度の高いものを作ろうとすれば多くの試験が必要で、対策コストも決して小さくないということは心に留めておくべきでしょう。 | |
|